Kafka와 Python을 통한 Data Migration
MySQL ➡️ Kafka ➡️ MongoDB
Kafka를 통해서 데이터 마이그레이션을 하는 방법은 다양한데, debezium을 사용할 수도 있고, spring 웹 개발 과정에서의 연동을 추가하거나, python script를 이용하는 방법 등이 있습니다. 오늘은 python script를 이용해서 데이터 마이그레이션을 하는 과정을 알아보겠습니다.
목차
- MongoDB Compass 설치 (선택)
- MongoDB 설치(Docker)
- MySQL 데이터 생성
- kafka 설치 & 토픽 생성
- python script 작성
- 실행&결과화면
MongoDB Compass 설치 (선택)
mongodb의 GUI 입니다. 셸에서 데이터를 조회해도 상관없습니다. https://www.mongodb.com/try/download/compass
MongoDB 설치(Docker)
docker mongodb container or mongodb atlas 중 mongodb를 실행할 타입을 선택합니다. 저는 docker를 통해서 연결해보겠습니다.
docker pull mongo
docker run --name mongodb -dp 27017:27017 mongo
docker container를 통해서 실행한 mongoDB에 connect해줍니다.
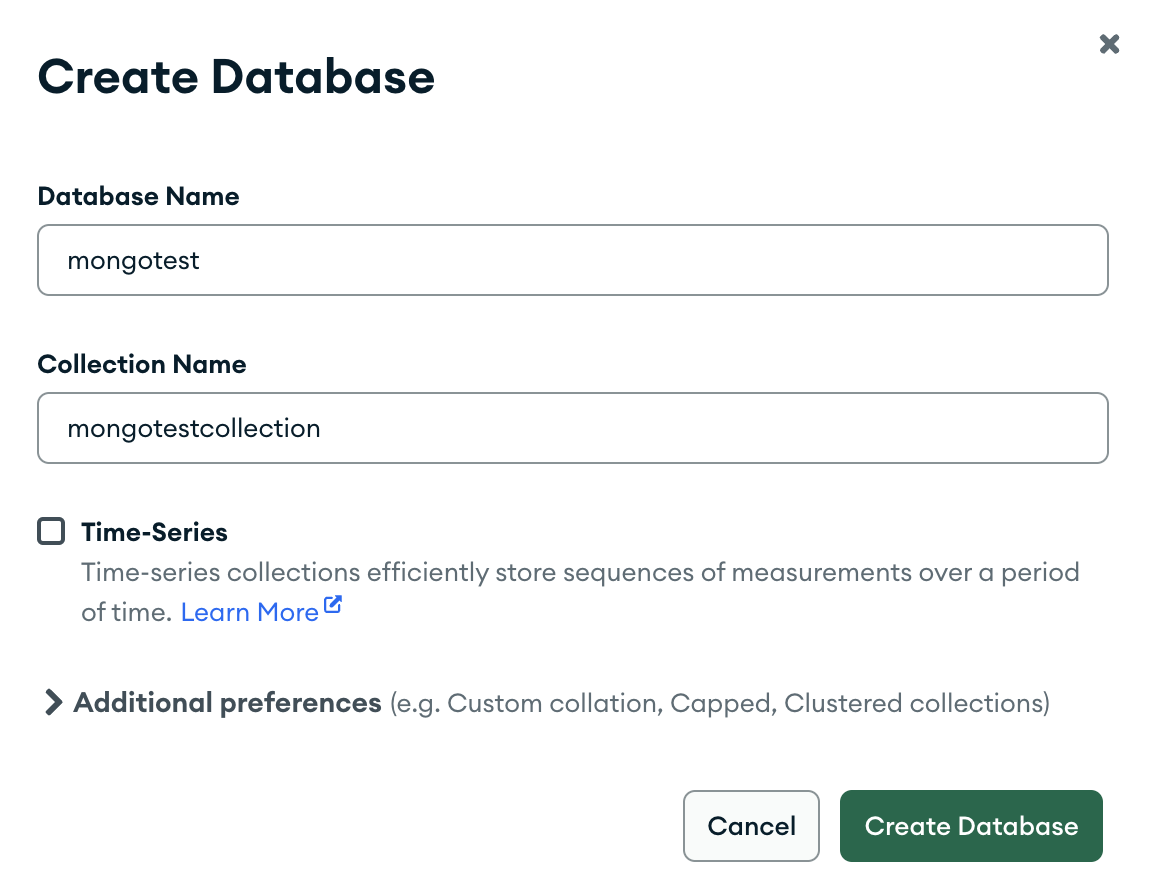
MongoDB Compass에서 작업에 사용할 데이터베이스와 컬렉션을 생성해줍니다.
MySQL 데이터 생성
작업에 진행할 테스트 데이터를 생성해줍니다.
데이터베이스 이름: kafka
CREATE TABLE post_tags (
id INT AUTO_INCREMENT PRIMARY KEY,
count INT,
info VARCHAR(255),
item_name VARCHAR(255),
price FLOAT,
todaycount INT
);
CREATE TABLE post (
id INT AUTO_INCREMENT PRIMARY KEY,
count INT,
info VARCHAR(255),
item_name VARCHAR(255),
price FLOAT,
todaycount INT
);INSERT INTO post_tags (count, info, item_name, price, todaycount) VALUES
(10, 'Sample post tags info 1', 'Sample item 1', 100.0, 5),
(20, 'Sample post tags info 2', 'Sample item 2', 200.0, 8),
(30, 'Sample post tags info 3', 'Sample item 3', 300.0, 12);
INSERT INTO post (count, info, item_name, price, todaycount) VALUES
(15, 'Sample post info 1', 'Sample item 4', 150.0, 3),
(25, 'Sample post info 2', 'Sample item 5', 250.0, 6),
(35, 'Sample post info 3', 'Sample item 6', 350.0, 9);kafka 설치 & 토픽 생성
kafka는 docker-compose를 통해서 설치해주겠습니다. 해당 내용으로 docker-compose를 백그라운드로 실행합니다.
docker-compose up -d
docker-compose.yml
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock생성한 컨테이너 bash에 접속해서, 'MongoMysql' 이란 이름의 토픽을 생성해줍니다.
docker exec -it kafka /bin/bash
kafka-topics.sh --create --topic MongoMysql -- bootstrap-server localhost:9092 --replication-factor 1
python script 작성
python script를 통해서 kafka의 producer와 consumer를 생성하여 데이터 마이그레이션을 진행합니다.
producer.py에서 host, user, password, database를 설정해주고, 사용할 kafka topic, 마이그레이션 할 table name 등을 설정해줍니다.
사용할 토픽의 이름: 52, 65번째 줄의
kafka_producer_post_tags = KafkaProducerWrapper(topic='MongoMysql')
producer.py
from kafka import KafkaProducer
from json import dumps
import mysql.connector
from datetime import datetime
class MySQLData:
def __init__(self, host, user, password, database):
self.connection = mysql.connector.connect(
host=host,
user=user,
password=password,
database=database
)
self.cursor = self.connection.cursor()
def fetch_data(self, table_name):
query = f"SELECT * FROM {table_name}"
self.cursor.execute(query)
columns = [column[0] for column in self.cursor.description]
result = [dict(zip(columns, self._convert_to_serializable(row))) for row in self.cursor.fetchall()]
return result
def _convert_to_serializable(self, row):
serializable_row = []
for item in row:
if isinstance(item, datetime):
serializable_row.append(item.strftime('%Y-%m-%d %H:%M:%S'))
else:
serializable_row.append(item)
return serializable_row
class KafkaProducerWrapper:
def __init__(self, topic):
self.producer = KafkaProducer(
acks=1,
compression_type='gzip',
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
self.topic = topic
def send_data(self, data):
self.producer.send(self.topic, value=data)
self.producer.flush()
def main():
mysql_data_post_tags = MySQLData(host='localhost',
user='root',
password='123qwe',
database='kafka')
kafka_producer_post_tags = KafkaProducerWrapper(topic='MongoMysql')
data_to_send_post_tags = mysql_data_post_tags.fetch_data(table_name='post_tags')
for data in data_to_send_post_tags:
kafka_producer_post_tags.send_data(data)
print(f"Data sent to Kafka (post_tags): {data}")
mysql_data_post = MySQLData(host='localhost',
user='root',
password='123qwe',
database='kafka')
kafka_producer_post = KafkaProducerWrapper(topic='MongoMysql')
data_to_send_post = mysql_data_post.fetch_data(table_name='post')
for data in data_to_send_post:
kafka_producer_post.send_data(data)
print(f"Data sent to Kafka (post): {data}")
if __name__ == "__main__":
main()consumer.py코드에서는 사용할 db와 collection이름을 지정해주어야 합니다. MongoDB Compass를 통해서 만들었던 이름을 사용합니다. 10~11번째 줄에서 지정해줍니다.
self.db = self.client['mongotest']
self.collection = self.db['mongotestcollection']
또한 컨슈머에서 어떤 토픽을 사용할지 지정해주어야 합니다. 18번째 줄에서 지정해줍니다.
self.consumer = KafkaConsumer('MongoMysql',
(+) 추가적으로 MongoDB를 컨테이너가 아닌 atlas를 통해 사용하고 있다면, connect url을 입력해줍니다.
self.client = pymongo.MongoClient("mongodb+srv://atlas_user:atlas123@mycluster.p0ytpkn.mongodb.net/?retryWrites=true&w=majority")
consumer.py
from kafka import KafkaConsumer
from json import loads
import datetime
import pymongo
class Mongodb():
def __init__(self):
self.client = pymongo.MongoClient("mongodb://localhost:27017")
self.db = self.client['mongotest']
self.collection = self.db['mongotestcollection']
def insert(self, message):
self.collection.insert_one(message)
class Consumer():
def __init__(self):
self.consumer = KafkaConsumer('MongoMysql',
bootstrap_servers=['localhost:9092'],
auto_offset_reset="earliest",
enable_auto_commit=False,
group_id='my-group', # 컨슈머 그룹핑(Fail Over, Offset 관리)
value_deserializer=lambda x: loads(x.decode('utf-8')),
consumer_timeout_ms=1000)
def print_message(self, message):
topic = message.topic
partition = message.partition
offset = message.offset
timestamp = message.timestamp
datetimeobj = datetime.datetime.fromtimestamp(timestamp / 1000)
print("Topic:{}, partition:{}, offset:{}, datetimeobj:{}"
.format(topic, partition, offset, datetimeobj))
def run(self, mongodb_obj):
while True:
for message in self.consumer:
self.print_message(message)
mongodb_obj.insert(message.value)
self.consumer.commit()
def main():
Consumer().run(Mongodb())
if __name__ == "__main__":
main()코드 작성 후 관련 의존성들을 pip3을 통해서 설치해주었습니다.
consumer.py를 실행시켜줍니다. consumer는 현재 producer에서 데이터 전송이 이루어질때까지 대기하는 프로세스를 수행하기 때문에 데이터 전달이 없으면 아무런 콘솔이 찍히지 않습니다.
consumer.py 실행 이후에 producer.py를 실행시켜줍니다.
이를 MongoDB Compass와 terminal을 통해서 확인해보겠습니다.
실행&결과화면
consumer를 실행시킨 모습
producer.py를 실행시킨 모습
consumer 터미널에도 관련 콘솔을 확인할 수 있습니다.
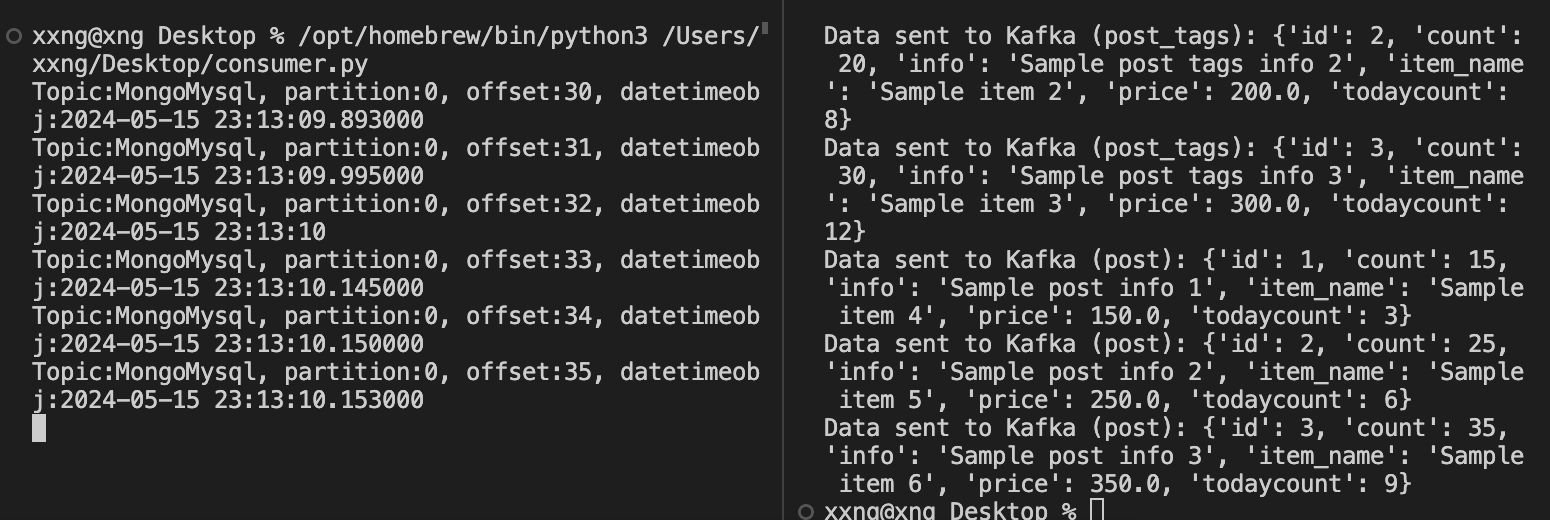
MongoDB Compass에서 확인한 모습
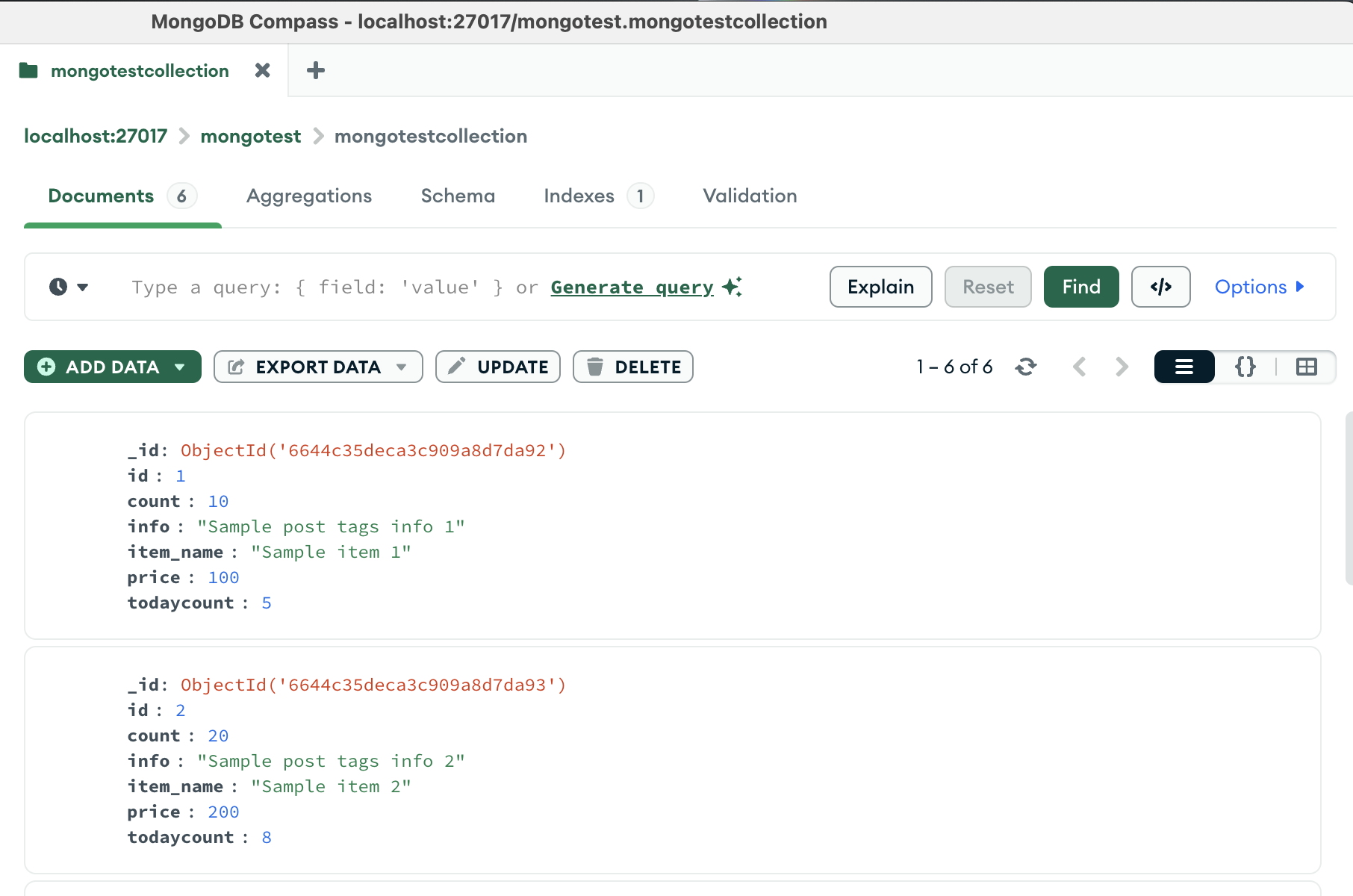 document가 6개 마이그레이션 된 모습을 확인할 수 있습니다.
document가 6개 마이그레이션 된 모습을 확인할 수 있습니다.
현재는 중복된 데이터를 확인하는 절차와 수정된 데이터가 있는지 확인하는 프로세스가 없는데, 따라서 producer.py가 실행될 때 마다 document가 계속 생성됩니다. 이 프로세스 또한 python 스크립트에서 추가하여 업데이트를 감지하는 로직을 구현할 수 있습니다.
먼저 중복된 데이터를 확인하는 절차를 추가해보겠습니다. 함수를 수정해줍니다.
def insert(self, message):
# 중복 체크
if not self.collection.find_one({'id': message['id']}):
self.collection.insert_one(message)
print("Data inserted into MongoDB: {}".format(message))
else:
print("Duplicate data found. Skipping insertion.")(결과) 수정된 코드로 consumer를 작동시키니, document 삽입을 스킵하는 모습입니다.
Topic:MongoMysql, partition:0, offset:55, datetimeobj:2024-05-15 23:20:51.555000
Duplicate data found. Skipping insertion.이번에는 업데이트를 감지해보겠습니다. 코드를 수정합니다.
def insert(self, message):
existing_document = self.collection.find_one({'id': message['id']})
if existing_document:
# 중복된 값이 있을 경우 업데이트
result = self.collection.update_one({'id': message['id']}, {'$set': message})
if result.matched_count > 0:
print("Data updated in MongoDB: {}".format(message))
else:
print("Duplicate data found. Skipping insertion.")
else:
# 중복된 값이 없을 경우 삽입
self.collection.insert_one(message)
print("Data inserted into MongoDB: {}".format(message))mysql에서 post id값이 1인데이터의 count를 100으로 수정해주고 producer를 실행시켜줍니다.
(결과)
Data updated in MongoDB: {'id': 1, 'count': 100, 'info': 'Sample post info 1', 'item_name': 'Sample item 4', 'price': 150.0, 'todaycount': 3}
document가 늘어나지 않으며, 업데이트 된 데이터가 올바르게 마이그레이션 된 것을 확인할 수 있습니다.
여기까지 Python Script를 사용해서 데이터 마이그레이션을 진행해 보았는데, 해당 프로세스는 주기적으로 파일을 실행시키는 bash 파일을 만들어서도 사용 가능하고, 삭제 등의 로직 또한 추가할 수 있습니다.
(5초에 한 번씩 producer.py를 실행하는 스크립트)
while true
do
python kafka_producer.py
sleep 5
done